前言
最近看到有网友爬《王者荣耀》全英雄皮肤图,觉得挺有意思的;也顺便记录下自己在分析爬虫的过程。
正文
0x01分析
首先打开http://pvp.qq.com/web201605/herolist.shtml可以看到全英雄列表,F12进入调试模式。找到英雄对应的链接地址。
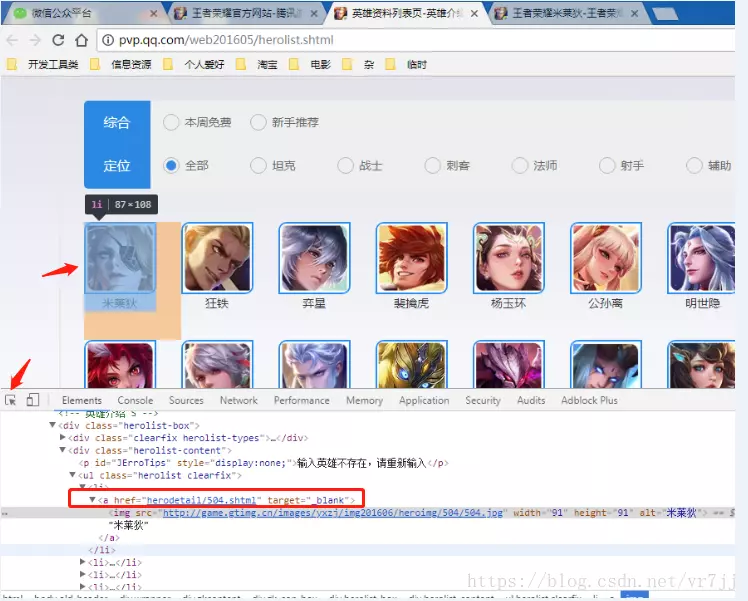
然后点进英雄后F12,选择对应的皮肤查询图片链接地址。这里取图片链接有有问题,后面代码实现详细说。
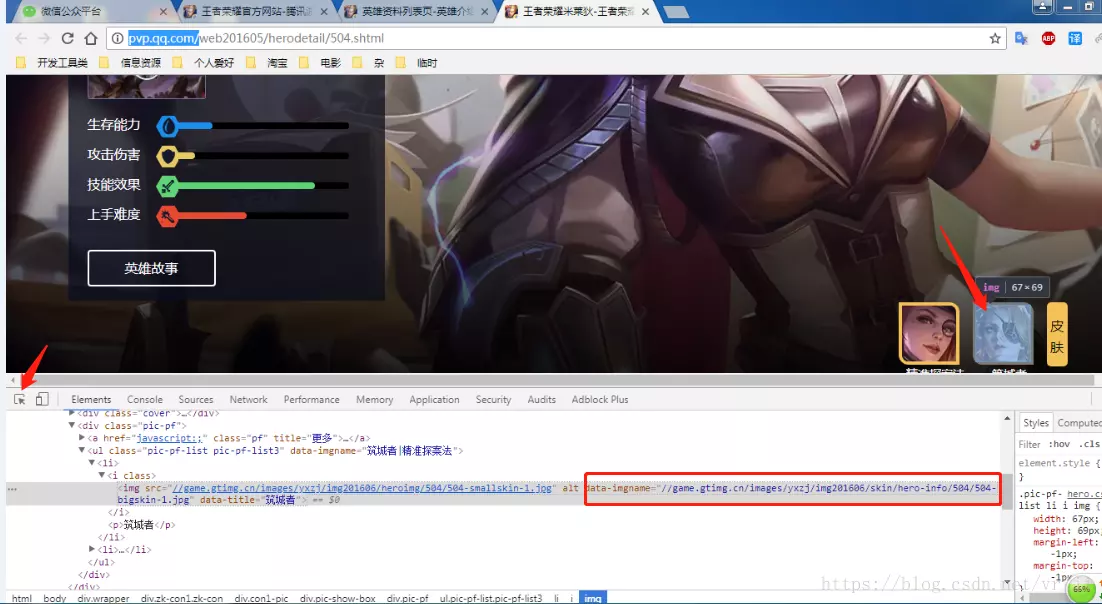
最后就是搜集链接地址,下载图片保存。
0x02代码实现
使用requests库抓取页面,使用BeautifulSoup分析返回的html。获取所有英雄的详细链接、名称和编号
import os
import re
import requests
from bs4 import BeautifulSoup
baseurl = 'http://pvp.qq.com/web201605'
mainurl = 'http://pvp.qq.com/web201605/herolist.shtml'
herolist = []
def getHeroList():
'''取所以英雄存入list中'''
hero = {}
res = requests.get(mainurl)
sp = BeautifulSoup(res.content, "html.parser")
lists = sp.select('body > div.wrapper > div > div > div.herolist-box > div.herolist-content > ul > li')
for li in lists:
oj = li.select('a')[0];
hero['url'] = oj['href']
hero['name'] = oj.text
# 正则表达式取ename编号
ename = re.findall('herodetail/(\d+)\.shtml', oj['href'])[0]
hero['ename'] = ename
herolist.append(hero)
hero = {}
return herolist
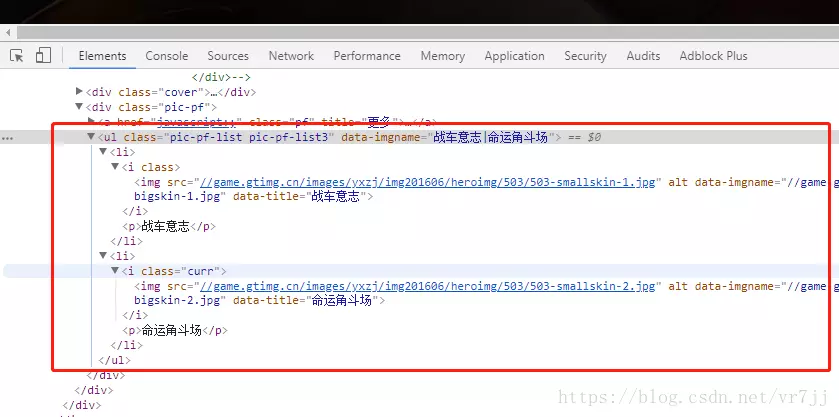
获取英雄皮肤图片链接,本以为会像“获取英雄链接”一样简单的,但我错了。通过代码获取的"英雄详细页“数据 和 浏览器F12看到的不一样。
代码获取的内容

浏览器F12下的内容
0x03问题分析与处理
猜想一
我首先想到的是cookies 和 headers 参数。但后面详细分析请求和几次尝试后问题还是没能解决。
猜想二
怀疑是页面ajax异步请求获取的地址。但分析后并未找至ajax请求数据。
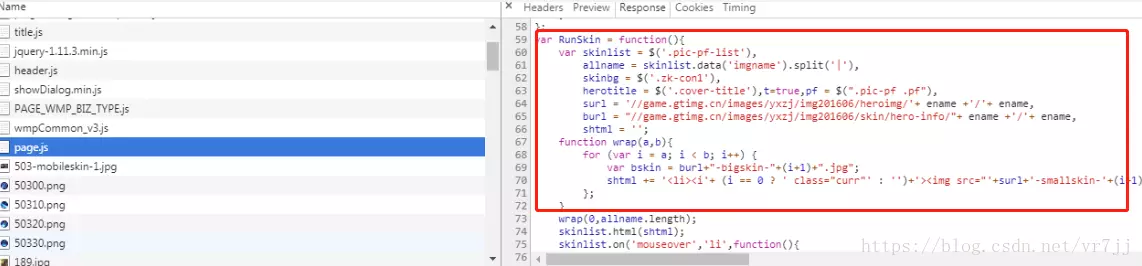
问题确定
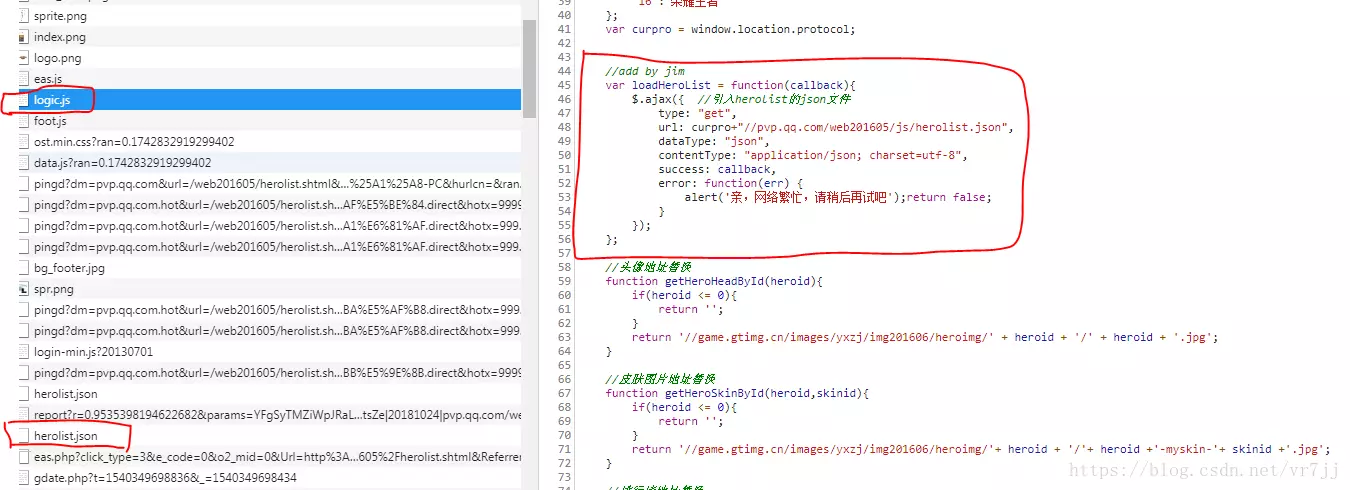
后来详细看了几个 js文件才找至答案。图片链接是js中生成。
0x04爬虫的实现
for hero in herolist:
herodir = os.path.join(os.getcwd(), hero['name'])
heropage = baseurl + '/' + hero['url']
print('------------%s---%s-----------' % (herodir, heropage))
res = requests.get(heropage)
sop = BeautifulSoup(res.content, "html.parser")
li = sop.select('body > div.wrapper > div.zk-con1.zk-con > div > div > div.pic-pf > ul ')[0]['data-imgname']
print(li)
li = str(li).split('|')
print(li)
# 遍历所有皮肤
for i in range(len(li)):
# 生成图片链接
imgurl = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/' \
+ hero['ename'] + '/' + hero['ename'] + '-bigskin-' + str(i + 1) + '.jpg'
imgname = os.path.join(herodir, li[i]+".jpg")
print('----[%s]--[%s]---' % (imgname, imgurl))
# 创建英雄目录
if os.path.exists(herodir) == False:
os.mkdir(herodir)
saveImg(imgname, imgurl)
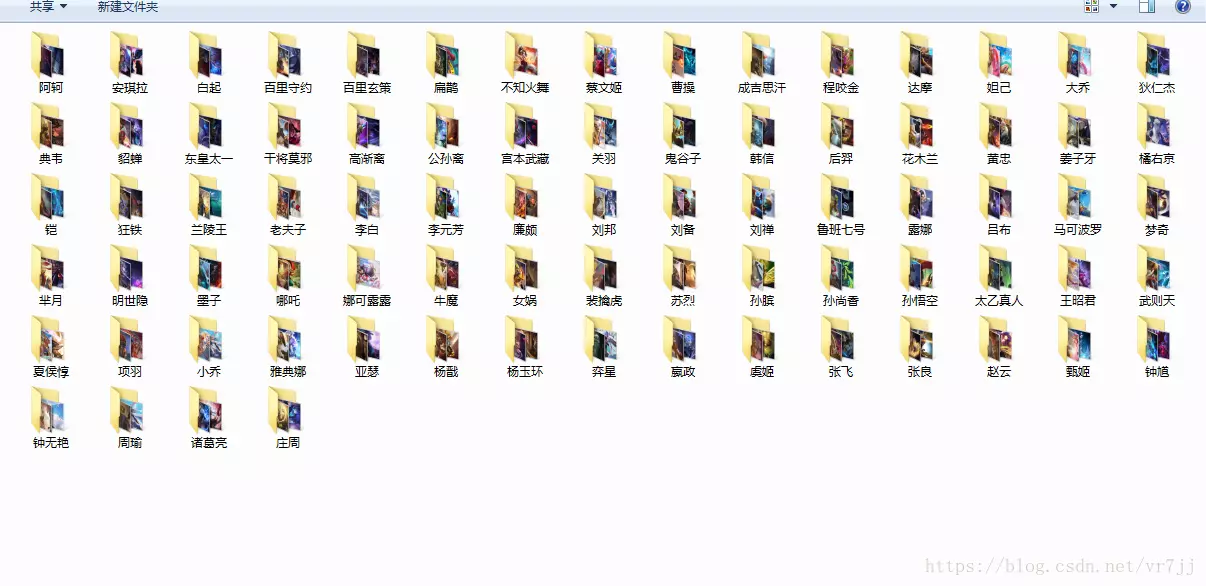
====== 20181024更新 =====
有朋友反应已经不能正常爬取图片,今天维护下。发现页面中的herolist已经改成ajax异步获取。同步下代码给有需要的朋友
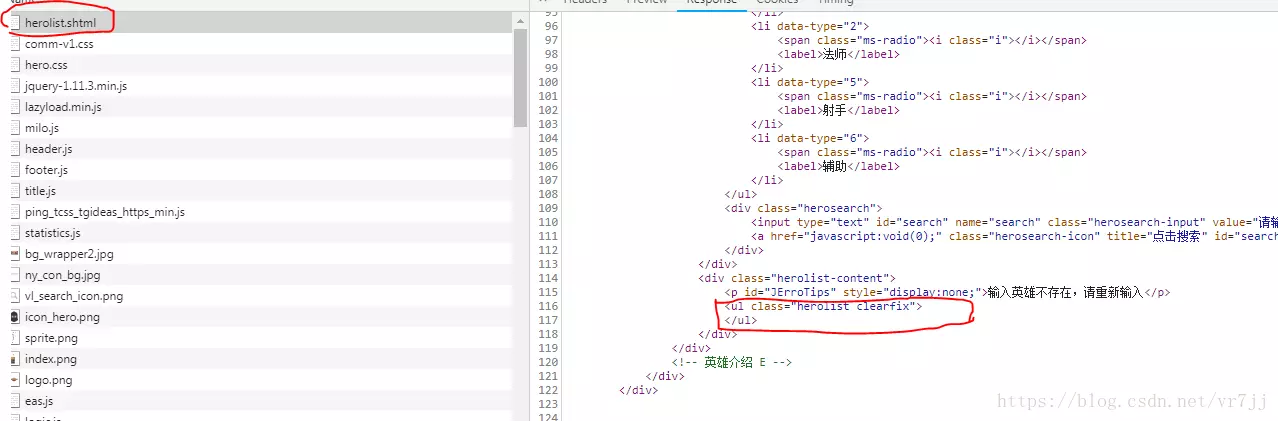
两图说明下ajax的过程
环境说明
python3.6 requests bs4 json
最新代码
链接: https://pan.baidu.com/s/17FP1jom16VvXHc0AJkkIGA 密码: 5i5u