前言
看了些Linux内存管理的文章,写一写加深对内存管理的印象。
正文
程序的存储
ELF是Linux的主要可执行文件格式。ELF文件由4部分组成,分别是ELF头(ELF header)、程序头表(Program header table)、节(Section)和节头表(Section header table)。具体如下:
- Program header描述的是一个段在文件中的位置、大小以及它被放进内存后所在的位置和大小。即要加载的信息;
- Sections保存着object 文件的信息,从连接角度看:包括指令,数据,符号表,重定位信息等等。在图中,我们可以看到Sections中包括:
- text 文本结 存放指令;
- rodata 数据结 readonly;
- data 数据结 可读可写;
- Section头表(section header table)包含了描述文件sections的信息。每个section在这个表中有一个入口;每个入口给出了该section的名字,大小,等等信息。相当于 索引!
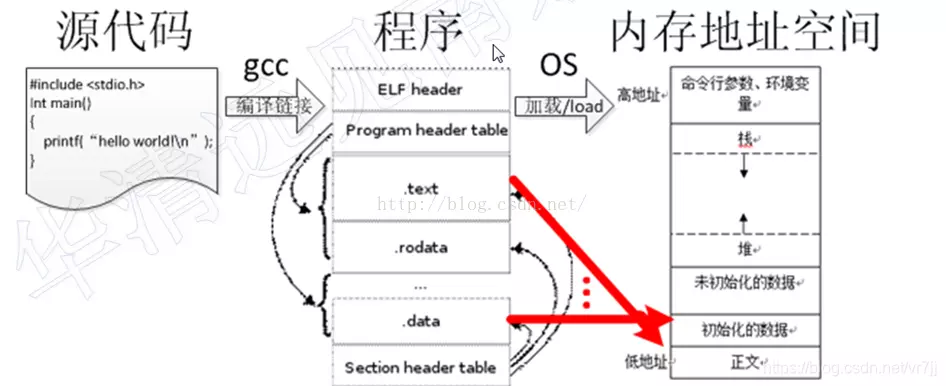
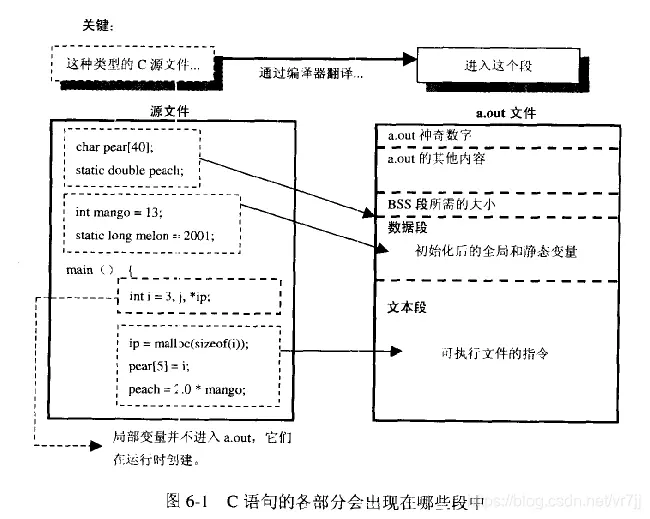
代码编译和存储
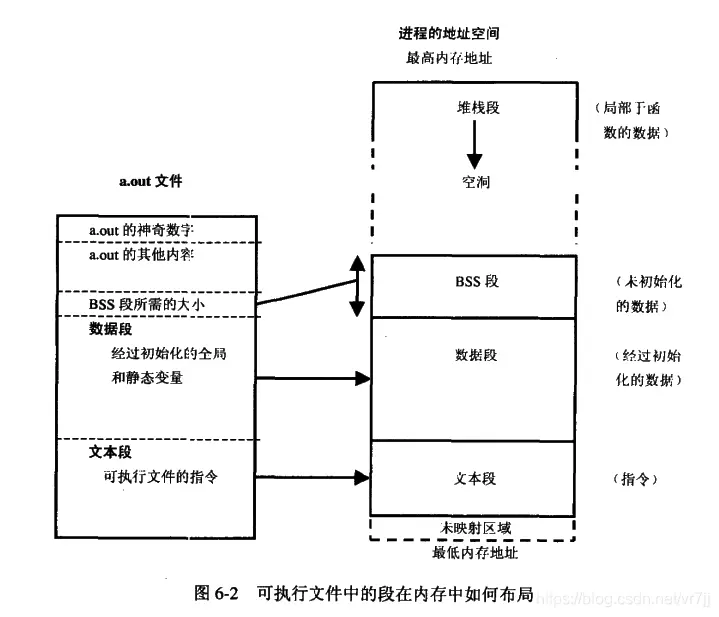
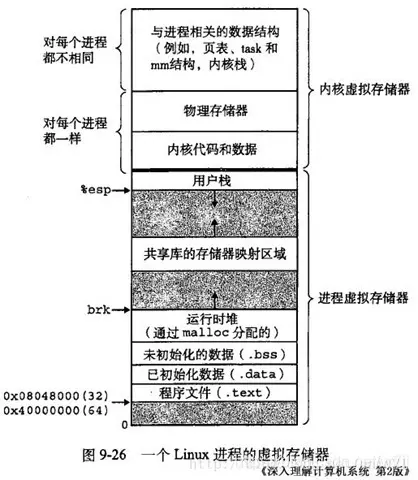
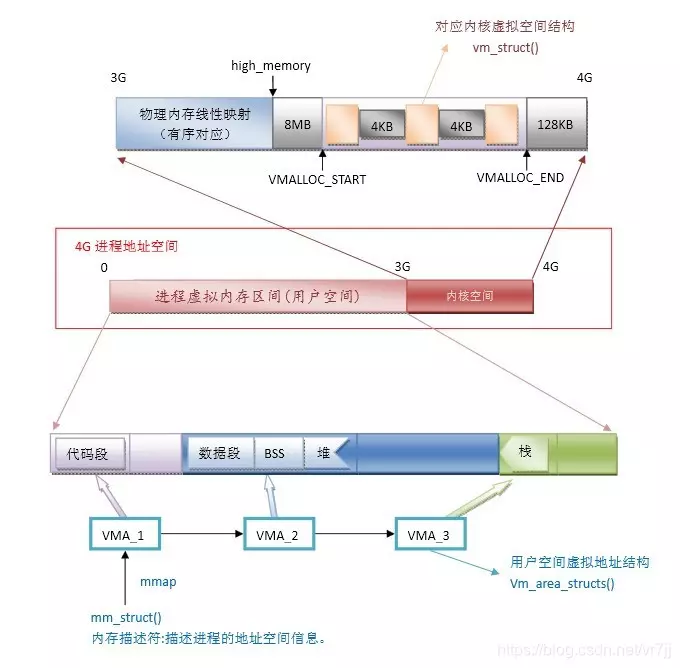
Linux 虚拟地址空间如何分布?
Linux 使用虚拟地址空间,大大增加了进程的寻址空间,由低地址到高地址分别为:
- 只读段:该部分空间只能读,不可写;(包括:代码段、rodata 段(C常量字符串和#define定义的常量) )
- 数据段:保存全局变量、静态变量的空间;
- 堆 :就是平时所说的动态内存, malloc/new 大部分都来源于此。其中堆顶的位置可通过函数 brk 和 sbrk 进行动态调整。
- 文件映射区域:如动态库、共享内存等映射物理空间的内存,一般是 mmap 函数所分配的虚拟地址空间。
- 栈:用于维护函数调用的上下文空间,一般为 8M ,可通过 ulimit –s 查看。
- 内核虚拟空间:用户代码不可见的内存区域,由内核管理(页表就存放在内核虚拟空间)。
下图是 32 位系统典型的虚拟地址空间分布(来自《深入理解计算机系统》)。
char *a 与char a[] 的区别
char *d = “hello” 中的d是指向第一个字符‘h’的一个指针;char s[20] = “hello” 中数组名s也是指向第一个字符’h’的指针。现执行下列操作:strcat(d, s)。把字符串加到指针所指的字串上去,出现段错误。本质原因:*d=“hello"存放在常量区,是无法修的。而数组是存放在栈中,是可以修改的。 两者区别如下: 读写能力:char *a = “abcd"此时"abcd"存放在常量区。通过指针只可以访问字符串常量,而不可以改变它。而char a[20] = “abcd”; 此时 “abcd"存放在栈。可以通过指针去访问和修改数组内容。
赋值时刻:char *a = “abcd"是在编译时就确定了(因为为常量)。而char a[20] = “abcd”; 在运行时确定
存取效率:char *a = “abcd”; 存于静态存储区。在栈上的数组比指针所指向字符串快。因此慢,而char a[20] = “abcd"存于栈上,快。 另外注意:char a[] = “01234”,虽然没有指明字符串的长度,但是此时系统已经开好了,就是大小为6—–‘0’ ‘1’ ‘2’ ‘3’ ‘4’ ‘5’ ‘\0’,(注意strlen(a)是不计’\0’)
结束
初步了解了程序的存储结构和运行结构。分享给和我一样还不太了解的朋友。一步一个脚印 . . .
参考:
linux环境内存分配原理 mallocinfo Linux系统内存管理 Linux内存管理(最透彻的一篇) Linux C 内存管理 深入理解C语言内存管理